
November 3, 2016
A new package isdparser is
on CRAN. isdparser was in part liberated from rnoaa,
then improved. We’ll use isdparser in rnoaa soon.
isdparser does not download files for you from NOAA’s ftp servers. The
package focuses on parsing the files, which are variable length ASCII strings
stored line by line, where each line has some mandatory data, and any amount
of optional data.
The data is great, and includes for example, wind speed and direction, temperature, cloud data, sea level pressure, and more. Includes data from approximately 35,000 stations worldwide, though best coverage is in North America/Europe/Australia. Data go all the way back to 1901, and are updated daily.
However, the data is not fun to parse, warranting an packge to deal with the parsing.
 Installation
Installation
install.packages("isdparser")
If binaries aren’t available, try from source:
install.packages("isdparser", type = "source") or from GitHub:
devtools::install_github("ropenscilabs/isdparser")
library(isdparser)
library(dplyr)
Parse individual lines
If you want to parse individual lines, use isd_parse_line()
First, let’s get a ISD file. There’s a few that come with the package:
path <- system.file('extdata/024130-99999-2016.gz', package = "isdparser")
Read in the file
lns <- readLines(path, encoding = "latin1")
Parse a line
isd_parse_line(lns[1])
#> # A tibble: 1 × 42
#> total_chars usaf_station wban_station date time date_flag
#> <dbl> <chr> <chr> <date> <chr> <chr>
#> 1 54 024130 99999 2016-01-01 0000 4
#> # ... with 36 more variables: latitude <dbl>, longitude <dbl>,
#> # type_code <chr>, elevation <dbl>, call_letter <chr>, quality <chr>,
#> # wind_direction <dbl>, wind_direction_quality <chr>, wind_code <chr>,
#> # wind_speed <dbl>, wind_speed_quality <chr>, ceiling_height <chr>,
#> # ceiling_height_quality <chr>, ceiling_height_determination <chr>,
#> # ceiling_height_cavok <chr>, visibility_distance <chr>,
#> # visibility_distance_quality <chr>, visibility_code <chr>,
#> # visibility_code_quality <chr>, temperature <dbl>,
#> # temperature_quality <chr>, temperature_dewpoint <dbl>,
#> # temperature_dewpoint_quality <chr>, air_pressure <dbl>,
#> # air_pressure_quality <chr>,
#> # AW1_present_weather_observation_identifier <chr>,
#> # AW1_automated_atmospheric_condition_code <chr>,
#> # AW1_quality_automated_atmospheric_condition_code <chr>,
#> # N03_original_observation <chr>, N03_original_value_text <chr>,
#> # N03_units_code <chr>, N03_parameter_code <chr>, REM_remarks <chr>,
#> # REM_identifier <chr>, REM_length_quantity <chr>, REM_comment <chr>
By default you get a tibble back, but you can ask for a list in return instead.
Parsing by line allows the user to decide how to apply parsing across lines,
whether it be lapply style, or for loop, etc.
Parse entire files
You can also parse entire ISD files.
isd_parse(path)
#> # A tibble: 2,601 × 42
#> total_chars usaf_station wban_station date time date_flag
#> <dbl> <chr> <chr> <date> <chr> <chr>
#> 1 54 024130 99999 2016-01-01 0000 4
#> 2 54 024130 99999 2016-01-01 0100 4
#> 3 54 024130 99999 2016-01-01 0200 4
#> 4 54 024130 99999 2016-01-01 0300 4
#> 5 54 024130 99999 2016-01-01 0400 4
#> 6 39 024130 99999 2016-01-01 0500 4
#> 7 54 024130 99999 2016-01-01 0600 4
#> 8 39 024130 99999 2016-01-01 0700 4
#> 9 54 024130 99999 2016-01-01 0800 4
#> 10 54 024130 99999 2016-01-01 0900 4
#> # ... with 2,591 more rows, and 36 more variables: latitude <dbl>,
#> # longitude <dbl>, type_code <chr>, elevation <dbl>, call_letter <chr>,
#> # quality <chr>, wind_direction <dbl>, wind_direction_quality <chr>,
#> # wind_code <chr>, wind_speed <dbl>, wind_speed_quality <chr>,
#> # ceiling_height <chr>, ceiling_height_quality <chr>,
#> # ceiling_height_determination <chr>, ceiling_height_cavok <chr>,
#> # visibility_distance <chr>, visibility_distance_quality <chr>,
#> # visibility_code <chr>, visibility_code_quality <chr>,
#> # temperature <dbl>, temperature_quality <chr>,
#> # temperature_dewpoint <dbl>, temperature_dewpoint_quality <chr>,
#> # air_pressure <dbl>, air_pressure_quality <chr>,
#> # AW1_present_weather_observation_identifier <chr>,
#> # AW1_automated_atmospheric_condition_code <chr>,
#> # AW1_quality_automated_atmospheric_condition_code <chr>,
#> # N03_original_observation <chr>, N03_original_value_text <chr>,
#> # N03_units_code <chr>, N03_parameter_code <chr>, REM_remarks <chr>,
#> # REM_identifier <chr>, REM_length_quantity <chr>, REM_comment <chr>
Optionally, you can print progress:
isd_parse(path, progress = TRUE)
#> # A tibble: 2,601 × 42
#> total_chars usaf_station wban_station date time date_flag
#> <dbl> <chr> <chr> <date> <chr> <chr>
#> 1 54 024130 99999 2016-01-01 0000 4
#> 2 54 024130 99999 2016-01-01 0100 4
#> 3 54 024130 99999 2016-01-01 0200 4
#> 4 54 024130 99999 2016-01-01 0300 4
#> 5 54 024130 99999 2016-01-01 0400 4
#> 6 39 024130 99999 2016-01-01 0500 4
#> 7 54 024130 99999 2016-01-01 0600 4
#> 8 39 024130 99999 2016-01-01 0700 4
#> 9 54 024130 99999 2016-01-01 0800 4
#> 10 54 024130 99999 2016-01-01 0900 4
#> # ... with 2,591 more rows, and 36 more variables: latitude <dbl>,
#> # longitude <dbl>, type_code <chr>, elevation <dbl>, call_letter <chr>,
#> # quality <chr>, wind_direction <dbl>, wind_direction_quality <chr>,
#> # wind_code <chr>, wind_speed <dbl>, wind_speed_quality <chr>,
#> # ceiling_height <chr>, ceiling_height_quality <chr>,
#> # ceiling_height_determination <chr>, ceiling_height_cavok <chr>,
#> # visibility_distance <chr>, visibility_distance_quality <chr>,
#> # visibility_code <chr>, visibility_code_quality <chr>,
#> # temperature <dbl>, temperature_quality <chr>,
#> # temperature_dewpoint <dbl>, temperature_dewpoint_quality <chr>,
#> # air_pressure <dbl>, air_pressure_quality <chr>,
#> # AW1_present_weather_observation_identifier <chr>,
#> # AW1_automated_atmospheric_condition_code <chr>,
#> # AW1_quality_automated_atmospheric_condition_code <chr>,
#> # N03_original_observation <chr>, N03_original_value_text <chr>,
#> # N03_units_code <chr>, N03_parameter_code <chr>, REM_remarks <chr>,
#> # REM_identifier <chr>, REM_length_quantity <chr>, REM_comment <chr>
There’s a parallel option as well, coming in handy with the larger ISD files:
isd_parse(path, parallel = TRUE)
Visualize the data
Make better date + time
df <- res %>%
rowwise() %>%
mutate(
datetime = as.POSIXct(strptime(paste(date, paste0(substring(time, 1, 2), ":00:00")), "%Y-%m-%d %H:%M:%S"))
) %>%
ungroup
viz
# removing some outliers (obs, look into more for serious use)
library(ggplot2)
ggplot(df[df$temperature < 100,], aes(datetime, temperature)) +
geom_point() +
theme_grey(base_size = 18)
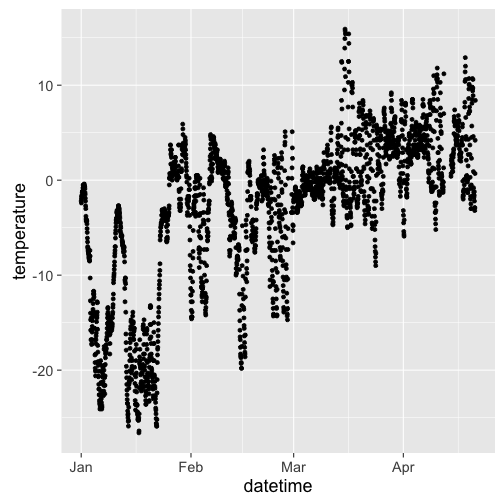
isdparser data
Future work
I plan to improve performance via profiling and swapping out slower code for faster, as well as possibly dropping down to C++.
There was already a featur request for asking for fields of interest instead of getting all fields, so that’s on the list.
Do try out isdparser. Let us know of any bugs, and any feature requests!
