
November 16, 2016
Optical character recognition (OCR) is the process of extracting written or typed text from images such as photos and scanned documents into machine-encoded text. The new rOpenSci package tesseract brings one of the best open-source OCR engines to R. This enables researchers or journalists, for example, to search and analyze vast numbers of documents that are only available in printed form.
People looking to extract text and metadata from pdf files in R should try our pdftools package.
 Getting Started
Getting Started
The package links to the libtesseract C++ library and works out of the box on Windows and Mac without installing any third party software.
install.packages("tesseract")
On Linux you first need to install libtesseract (readme) which ships with every popular distribution (Debian, Ubuntu, Fedora, CentOS, etc).
The package itself is very simple. The ocr function takes a URL or path or raw vector with image data. On most platforms the image should either be in png or jpeg or tiff format.
library(tesseract)
text <- ocr("http://jeroen.github.io/images/testocr.png")
cat(text)
Running this in R should recognize the text in the example image almost perfectly. The ocr function has one additional argument to set custom tesseract options. This is needed if you want to use custom or non-english training data (which we will explain below). The ?tesseract manual page has more information.
Why OCR is hard
Finding and classifying visual patterns is incredibly difficult for computers, especially if the picture contains noise or other artifacts. Humans take advantage of prior knowledge about the language that we use to “fill in the gaps” when reading text. For this reason recognizing text within a blurred or deformed image is a common CAPTCHA method to tell humans apart from computers.
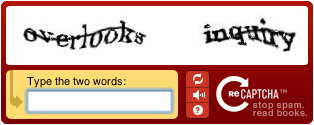
When using OCR to extract text from a document, the result will rarely be perfect. The accuracy of the results varies depending on the quality of the image. Obviously images used by CAPTCHA software are designed to be too difficult to recognize by state of the art OCR methods.
Context Language
A character can often only be recognized in the context of the word or sentence appears in. For example if a text contains the words In love the capital I and lower case l look (nearly) identical when printed.
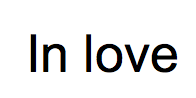
They can only be distinguished them from their context: both in and love are common words in English and a preposition may be followed by a noun. From from this context we can derive that the first character is most likely a capital I whereas the third character must be a lower case l.
text <- ocr("https://jeroen.github.io/files/inlove.png")
cat(text) # In love
The OCR method used by tesseract uses language specific training data to optimize character recognition. The default language is English, training data for other languages are provided via the official tessdata repository directory. On Linux these can be installed directly with the yum or apt package manager.
On Windows/MacOS you have to manually download training data for other langauges for now. The next version of the package will hopefully make this a little easier.
Optimizing Performance
Besides training data, the most important aspect of OCR performance is the quality of the input image. High resolution images with horizontal text, high contrast and little noise will achieve the best accuracy. The official Tesseract Wiki has some advice on how to improve the image quality.
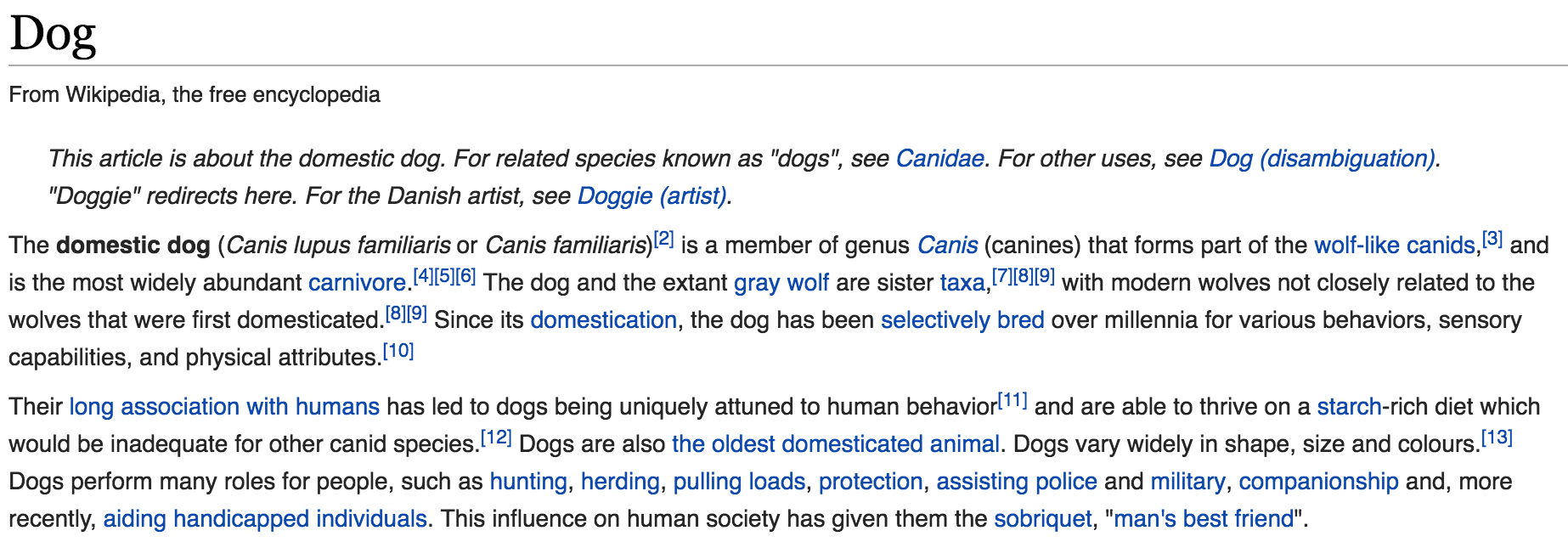
To put this to the test, we made two screenshots from the Wikipedia page above. The high quality image in the code below has approximately double the resolution of the low quality image. In addition the font rendering seems slightly better for the high quality image.
# Low quality:
text1 <- ocr("http://jeroen.github.io/files/dog_lq.png")
cat(text1)
# High quality:
text2 <- ocr("https://jeroen.github.io/files/dog_hq.png")
cat(text2)
Running this example in R shows that the accuracy of text extraction from the first image is very high but it dramatically decreases for the second image. Because Tesseract relies on the context to recognize characters, accuracy drops exponentially as increasingly many characters become blurry and ambiguous.
Future Plans
The current version of the ‘tesseract’ package is stable and essentially feature complete. We may release an update in the future to include additional utitlities for downloading and managing training data. These updates may also include some integration with the rOpenSci’s magick package to help with preprocessing images.
All of our development at rOpenSci is driven by user feedback. If you find a problem or have suggestions for improvement, we would love to hear about it on our Github page!
